| Time | Topic | Notes (these notes are not a verbatim transcription. The meeting discussion has been edited and summarized for readability) |
|---|
| - Please update your SIG(s) affiliation on the Bulk Edit home page
- Please add your name to the attendees list
| - Magda: I would like to Come to an agreement on expectations for the pilot project today.Magda: Please add your SIG affiliation to the Bulk Edit Homepage. It will help me if I need to reach out to you in your area of expertise.
- Magda: Also, please add yourself to the list of attendees on today's meeting page. At the last meeting, we had 14 people attending, and not all of the names were listed under the attendees.
|
| Development updates: | - Magda: Update on development – if you have not had a chance to take a look at snapshot or testing environment, take a look. Most of the progress available there is the UI. No work on the backend has been done yet. You will see a drop dropdown for the identifiers, the file drop area, a list of applications with bulk capabilities.
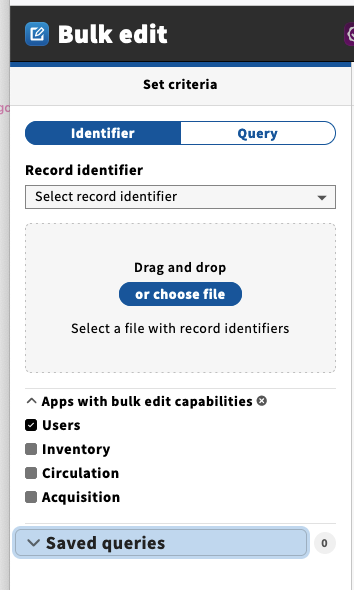
(screenshot taken post-meeting)
- The team is currently deeply involved in addressing issues from bugfest, which need to be resolved by next week, followed by retesting. So, this delays Bulk Edit implementation. But officially, Lotus development has not started yet, so they have a little time.
|
| Bulk Edit UX Research | - Magda: Regarding the bulk editing UX research that I posted on several channels, as you may recall, I was presenting two proposed bulk edit approaches. One option, the users will download a list of the records that match search criteria, make changes locally, and then upload the modified document. I referred to this approach as a CSV approach. The other approach is the app approach, where the user is guided through the whole process of editing records. Both approaches have pluses and minuses. For the pilot project, we decided to build using the CSV approach.
- Magda: But the in-app approach is not off the table by any means. In presenting the application to different SIGs, some were excited about downloading the records and making global changes because it gives the user a lot of flexibility. The other SIGs were not happy because they felt it was too much effort to put on the end-user, and it expects the user to be more technical. So I reached out to Ebsco's UX and user experience research group to help me to find out the best approach. The group scheduled several controlled interviews with librarians from Cornell, Duke, the University of Chicago, Five Colleges, Chalmers, and Stanford. Many of you who are in this group expressed interest in participating in the interviews. I will also sit in on some of those Interviews to get your feedback. But the data is collected and analyzed by a team that I do not belong to. So, I am looking forward to the findings. Once I have the findings, I will discuss them with the group.
- Leeda: I found it helpful to go back and look at your PowerPoint presentation on what the expectations were for the Bulk Edit Pilot, and I wondered if we could post them up on the Bulk Edit page somewhere.
- Magda: I will post them to our page.
- Sara: I was just wondering if the surveys/interviews will be done again when we move to other apps because I do feel like bulk editing is somewhat functionally dependent, and once we get to some of the other apps, there can be other things that could be surfaced.
- Leeda: I was a little worried that it looked like out of the five of us in the volunteering. Most of us are technical services and wouldn't really be handling the user data.
- Sara reiterated through using her personal experience that there may be quite different user needs depending on what area of the library the user is operating and the kind of records they are trying to edit with the application.
- Magda: I did review the use cases provided when I started the conversation, and there are common technical approaches to this. It was also covered in the presentation that I did for several SIGs that there are common elements among the record types and functional areas.
- Erin: In the case of users, it did go to the user management group for specific scenarios and discussions. We may not have seen that in this particular group, but there have been significant discussions about searching and locating records. Your point is correct and valid, but I think we have done some of that work outside the specific context of these meetings with Ebsoc's UX researchers.
- Sara: Going back to my first question, it was more about needing this kind of deep-dive when moving to the other apps.
- Magda: I agree queries types will vary by functional area but the overall process is the same. And yes, we will circle back to the groups when we start attacking the next functional areas. But once you select the records to do the edits this is the place where we have two possible approaches, the CSV approach, and the app approach, and the discussion is which one is better and what are pros and cons for each approach are. And this is the reason we have the UX research or controlled interviews.
- Reviewing changes, confirming changes, committing to changes, logging committed changes, and panel exceptions, are important to preserve data integrity
- Bob: Which SIG liked the CSV approach?
- Magda: My understanding was that the Metadata Management SIG really like this approach. But other comments came in and I decided to reach out to other groups.
- Leeda: I think what they liked about this is the flexibility to isolate records that need changes and understand dependencies and then push those record numbers back up. Then the changes happen in-app. Changes are not pushed up that happen in the app. People were more worried about the possibility of pushing changed data back up. This can open up more opportunities for error.
- Magga: This was taken into account by providing examples of errors. After processing the upload a list of works not able to be possible to be updated is presented.
- Leeda: That's good. Another thing that I think will be really important is really good detailed logs. We have a preview feature in Aleph. But also we need to really emphasize the logs up front and make sure it's telling us exactly what happened and what didn't happen.
- There was a question in chat about the testing environment. In response:
- Magda: problem in testing where the app does not always appear. The slides from the presentation have a good set of screenshots.
- Jennifer: Regarding the CSV approach, I think it's just like what Leeda and maybe Sarah said. A lot of what we work with is operational lists, for things like lists of call numbers or shelf listing, or even a list of student user accounts. So, it is really nice that we can download it. So, yeah. And the common, the center, just a postnup domestically that. It depends on what you try to do. Exactly. And this is the case, and this is what I got also from the, like presenting it to, um, resource access and sick where the, um, the bulk edits are done by students, uh, students.
- Sara (in chat): It really depends on what you are doing.
- Magda: Exactly. This is also what I got from the Resource Access SIG where Bulk Edit is used by students. Obviously, you don't want students to do the download and upload of the data. Instead, you want something straightforward.
- Magda (in response to chat from Jennifer): Jennifer posted something very important to me. If our approach is too technical, it will become the bottleneck because we can not expect that all librarians are technical, and then the work will not be done immediately and will have to wait for someone else to complete the work. So, um, I agree that we may need to have just two approaches to choose from depending on the task.
- Magda: The challenge with the in-app approach it takes a lot of development time. This will not be part of the pilot because there is not enough time. I also agree with Jennifer that we need to have easy-to-understand logs, and I will rely on your feedback to accomplish this.
|
| Surveys overview: | Magda: There were 11 responses to the "Bulk edit - currently used tools survey," including College of the Holy Cross, Cornell, Cornell Law, Duke University, GBV, Leipzig University, Michigan State University, Missouri State University, Stanford, and the University of Chicago. Magda: There was one thing that strikes me and this will be part of our next survey, many of you brought up the performance and the size of the data. There is no easy compromise. If you are editing a lot of data through the UI, it will be slow and will have an impact on other areas of the application. This has been coming up in other FOLIO apps. This is the technical thing that every app is struggling with. Magda: The question posed to you is what do you consider to be a large data set to edit in the UI? Would that be 10K, 100K, a million records? We need to know that. And we also need to know the expected processing time for those records. Erina: The most records we would probably edit at one time would be 80,000, and I would expect those updates. The timeframe depends on when you are doing it. We normally run our scripts overnight and would expect it to be done in an hour or two. But we have to be able to schedule that kind of work because if you were doing it during the day when the system is being used for other things, you could see slower behavior Leeda: For Duke on the technical service side, we recently did a cleanup project where we ran an overnight correction of about 250,000 bib records and it took about 3.5 hours. And then on the items side, I did one that was about 35,000 records where I changed the status to withdrawn. I'll have to look up how long that took, but it wasn't bad, but I'll have to get back to you on that one. - Magda: Did you do all of those in the application?
- Leeda: Yes. We identified the records we wanted to target and then ran the record identifiers through a service form with what the change was going to be. It was to insert a field into the bib records and then for the items, it was changing them to withdrawn. But yeah, those are the kinds of numbers we'll want to be able to do.
- Bob: Yeah, I would echo that at holy cross. We often will be correcting sets of MARC records, for instance, hundreds of thousands of ebook records, maybe to just change HTTP to HTTPS. I am not too concerned about how long it takes. I am more concerned about being able to do that kind of thing and just set it, and then walk away as long as it doesn't affect, the performance of the system and other areas like the end-users.
- Magda: Does that mean the duke has 80,000 users?
- Erin: Yes. Because it includes our hospital staff. Aaron Weller posted in chat that they have similar numbers that at Michigan, and I would expect a public library to have similar numbers if not higher.
- Magda: We will definitely spend a separate meeting talking about performance and record size, because to be honest, at this point, I don't expect 80,000 records to be more notified in one or two hours or 250K records in three hours. I don't think it's doable. Maybe I'm being pessimistic. Maybe it is possible. Obviously, we need to do more tests. But this is really good feedback.
- Magda: Scheduling is also on our list of things to discuss. It was also mentioned at some point in the Slack conversation. Obviously, you would like to do large jobs like this overnight.
- Mark: I'm loading about 30,000 records every night takes about 15 minutes. User records are really not too bad. Inventory, that's a whole different kettle of fish.
- Magda: But you are only adding records, not getting the records, modifying the records, and uploading and saving the records, right? And I think this is where we, uh, first to find the record, then make the change and then save the change. Well, suggesting that to do this would take 15 minutes, but I'm hopeful that it would take less than 60. Okay. Um, I really hope this is the case. And, uh, I agree with you. The user records may be.
- Mark: Well, I am not suggesting that to do this would take 15 minutes, but I'm hopeful that it would take less than 6 hours.
- Magda: I really hope this is the case. And, uh, I agree with you. The user records may be in a better place when it comes to performance than inventory. The data structure of inventory is more intertwined with other areas than users.
- Magda: But as I said, we will come back to this. I would really like us to start talking about expectations because, we are not all on the same page, and I would like us to get on the same page.
- Bob: In the Sierra system, the identifying of the records, is done separately. First, we would identify records by doing a search, either through a separate application called Create Lists or from within bulk edit application using the drop-down index search. When results come back then you run your change requests. I guess what I'm saying is it could be a little less intensive from the user's point of view if those things are separate steps in the workflow.
- Magda: These are separate in our approach as well.
|
| | - Magda: I would like to go back to the expectations of the pilot project.
- Magda: I agree with every single, response you provided, especially in the success criteria. However, not all of this is achievable in the scope of the pilot project. And I would like us to go one by one and have a discussion, maybe further discussion to narrow it down or to clarify. So we know what this meant.
- Erin: What what's in this list that you think is not achievable?
- Magda: A lot.
- Review of Survey - Success criteria for the pilot project:
- Meet requirements for use cases for editing fields in core user record;
- Magda: I agree but we still will need to review the use cases to be sure.
- Should we investigate a dashboard-type approach?
- Magda: We can investigate the dashboard approach, but I'm pretty sure this will not be in the scope of the pilot project.
- Mark: What do you mean by a dashboard approach?
- Erin—UI should look different depending on what you are doing and the type of records. Maybe a dashboard would be a useful way to approach how to accommodate all the different use cases for this app.
- Mark: I like this idea.
- Magda: I like this idea too. I met with Owen to see what can be used from their dashboard work. So this is still on the table. It is not on the table for the pilot project.
- Thomas: One of the things I was thinking about is a way of creating something that would not put as much burden on the back-end coders. One solution would be to allow admins for a tenant to create their own forms. Instead of the programmers trying to create a form for every single app they would create a structure that allows that to be done locally. For example, an admin could go in and set up a form that allows somebody to scan in barcodes and then change locations. The admin would set up a search form that the end-user would use to pull the records and then set up an update form that would display the parts of those records that they could then update and then save that and they would be able to access it.
- Magda: So this is an interesting suggestion. In terms of the scope for the pilot project though, the pilot project does not intend to have settings for bulk edit, but this is definitely a good example. This is an interesting idea, but it may not be for the pilot.
- Determine which use cases should be met in the Bulk Edit app and which are more appropriate in other contexts.
- Magda: This is also a good one. And I think this is something we should discuss as a group, which use cases will be covered by the Bulk Edit Pilot project and which one will be addressed later.
- That the agreed-upon user actions complete reliably and successfully.
- Magda: Hard to disagree with this. But this is a pretty generic comment. What is successful for me and reliable may not be reliable for users. Any comments?
- Jenn: It would be good to know what more is needed to fill out that requirement. I would say that what I need to not happen is another data import situation. So I don't want this to make my life worse. If we say that the app can change a hundred thousand records and what it does is make 20% errors, that would make it worse for me. What it does do, should work. Less is OK, as long as it works! It should be reliable and accurate in what it does do.
- Magda: So Jen, I think we are on the same page. The scope should be small for the pilot project but cover all the elements so we know we are not compromising data integrity.
- Ability to do update a list of records without compromising performance or data integrity.
- Magda: I can agree with the data integrity. I can also agree with compromising performance because as we said before, there is not enough time for us to invest in the proper performance. So, the performance may be slow. We can address this later, or we can just limit the pilot project to a very small dataset.
- Leeda: I think we'd all agree on needing dating accuracy and consistency. We can build on the performance later. We don't want it to do the wrong thing really fast.
- Magda: Exactly. We don't want to have a lot of protocols updated incorrectly.
- Sara: I think that there are two performance issues. There is the time it takes to update a batch of records and then there is the overall performance of the system. I don't want to set something off that brings everything else to a screeching halt. I think we definitely need to keep the overall performance in mind.
- Magda: I agree with you, Sarah. For the pilot project, we can maybe just state that you can process say only a thousand records at once to make sure that we are not affecting the system performance. Limitations need to be documented.
- Magda: Performance testing and performance tuning are very time-consuming. It's definitely worth investing the time, but I don't see this happening in the scope of the pilot. I would like us to look at the pilot as a sampling of what can be done.
- Produce a module/software that can update or delete a circumscribed set of data.
- Magda: We will not be able to do deletion. We will be able to do updates, but deleting is out of scope for the pilot.
- I suppose the success criteria is being able to perform a nuanced form of ETL, by extracting identifiers and defining the edits, without introducing error, affecting User privacy, or interrupting business logic. In addition, this needs to happen at scale, with accuracy, efficiency, and detailed logs.
- Bulk edits have accurate and predictable results;
- Magda: Bullets #7 and #8 are in reference to the enforcement of data integrity. And, we all agree on this, but I think it's not very specific when it comes to the pilot project.
- Leeda: You can tell a lot of us are coming from data important.
- bulk edits do not obviously degrade system performance; if limits must be placed on bulk edits to preserve system performance those limits are known and enforced;
- Magda: This is again, the case of data integrity. Edits do not obviously degree system performance. If there are limits and most likely for the pilot project projects, there will be limits, they will be documented.
- bulk edits produce accurate and accessible logging information; bulk edits are appropriately controlled by permissions;
- Magda: This is definitely true. And I agree this needs to be a part of the pilot project so use or know what to expect.
- bulk edit has an interface that is usable and understandable enough to not cause user misunderstanding or errors.
- Magda: I agree with you and this is basically the job of this group. So whatever is implemented, I will ask you for quick feedback. If something does not make sense, please let me know as quickly as you can. We will also be regularly reviewing the state of the UI. So this will be the time for you to raise the flag. Also, I will ask you to do some exploratory testing as well and to provide feedback.
- The ability to bulk edit some part of the record and have all the associated reporting.
- Magda: I think if you understand the reporting logs that were mentioned in the mock-ups then definitively this is a part of being about bulk edit.
- Demonstrates the ability to identify records for the update, specify changes, and implement the changes for both repeatable and non-repeatable properties and for replacing data.
Magda: Repeatable and not repeatable properties have been mentioned before in our technical design, This is something we will need to be cognizant of. Whatever is in the scope of UXPROD-3225 will be implemented.
- Identified functions can be executed in a test environment.
- Magda: Not sure what this is. Whoever provided this, I would appreciate the additional information.
- I can add, delete, and replace data in a batch of records after isolating the group of records via an index search, or loading of a list of identifiers.
- . I agree with that, with the exception of delete. Delete is out of scope for the pilot project.
- Review of Survey - Who should evaluate:
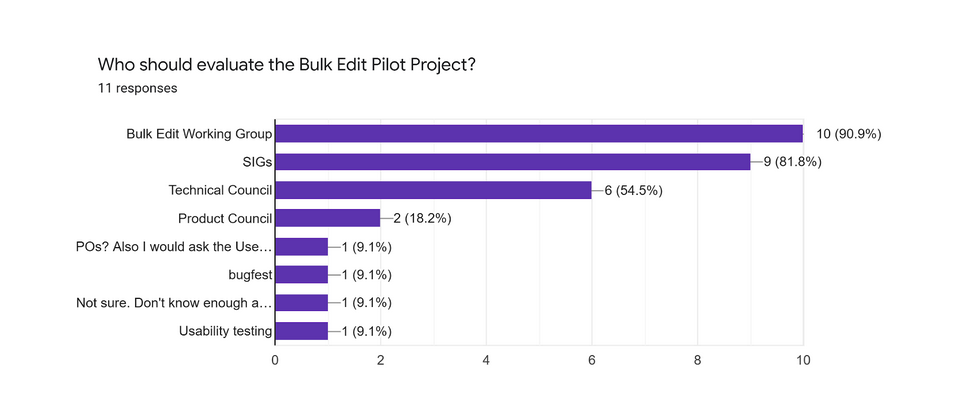 - Magda: This group will need to be the main evaluator. Definitely agree that the product council should have their say considering the data integrity implications of Bulk Edit.
- Magda: Product Council–I do not have experience with another product council. So I would rely on you to tell me why do you think this is important. But if needed definitely.
- Magda: Usability testing will be happening as we develop.
- Magda: Bugfest I will address in the next question.
- Magda: POs–I am in touch with POs. But if you imagine a more structured approach to communicating let me know.
- Magda: We only have three minutes left. I think we will continue this next meeting.
- Review Survey – What environment:
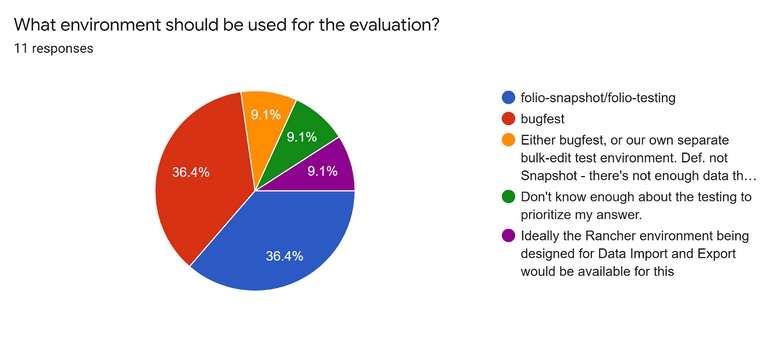 - A quick review of the environments:
- Magda: Obviously, the one was the folio snapshot and folio testing. This is a must. We definitely need to have these environments.
- Magda: Bugfest to be included would have to be included in a release. So if the app is mature enough that it can be included in the Lotus release, then this will be definitively an option.
- Magda: Another option was a Rancher environment that is being designed for data import and export. And I disagree with this approach because of the data issues already mentioned. If we add a new application on this, we will never know if the data integrity issue that we are observing is coming from the data or coming from Bulk Edit.
- Magda: However, I agree that we need to have a separate environment and I will reach out to whoever I need to, to create a separate rancher environment with will be designated for Bulk Edit testing, which probably will have this data that is in the bugfest testing environment, but will have more data than is in FOLIO snapshot testing environment and will not be refreshed but persist.
- Leeda: That sounds good Magda. That was me on the Rancher. It was primarily because of the way snapshot is emptied out every day of all the data. I wanted a more stable area, but you brought up a good point about having data import in there and all the things going on; it might confuse things. So if we could get a parallel environment that retains data and is cleaner, that would be ideal.
- Magda: I will keep you informed about the progress. I want to emphasize that this is not something that happens quickly with the Rancher environment, but I know when we developed the Elasticsearch environment, we used the team's Rancher environment with approximately 50,000 records. It was more than in a snapshot and the data was not refreshed, so that helped us a lot.
- Magda: I will post a proposal based on expectations and post it to Slack for discussion so we don't lose two weeks. And then at the next meeting, we can progress to other elements that are on our list to discuss, e.g., permissions, and related records.
- Magda: The next survey will be on max records which we touched on today.
- Magda: If there is anything else you would like me to address at the next meeting, reach out to me on Slack. Thank you all for your time.
|
| Future discussion topic (time permitting): - Bulk Edit Permissions
- Bulk Edit of the linked records
- Max number of records to be edited via User Interface
- Scheduling edits
|
|