Bulk Operations redesign
| Role | Person | Comments |
|---|---|---|
| Solution Architect | ||
| Java Lead | ||
| UI Lead | ||
| Product Owner |
Summary
This solution design document aims to provide details for the Bulk Operations module implementation that will be used as a basis for further Bulk Edit & Bulk Delete features.
Requirements
Bulk Operations (Edit/Delete) will be a complex application to modify and delete different entities in bulks.
- The current implementation resides in the mod-data-export-worker module. This functionality must be moved into a separate module to create a sustainable basis for further feature development.
- Expected volumes of data to be processed:
- there is a confluence page that contains the volumes of data that are processed by the different institutions. Volumes vary greatly by institution. Bulk Edit - edited data size
- For the Orchid release, the Bulk Operation application must support the processing of up to 50,000 records by one operation.
- there is a confluence page that contains the volumes of data that are processed by the different institutions. Volumes vary greatly by institution. Bulk Edit - edited data size
- Expected execution time:
- It is clear that the processing of big datasets could take some significant time, up to several hours. For the Orchid release, there is no strict requirement for the execution time. This discussion will continue after we get real results from the production environment for the Orchid release.
Functional requirements
During bulk edit users should be able to identify records based on a list of submitted identifiers or by building a query and have the ability to change one or more properties for each record. The supported updates include changing and removing existing and adding new values. The bulk edit functionality includes also bulk deletion. Bulk adding of new records is currently out of scope for this feature.
Before any changes are committed, users should be able to review them, confirm them and then commit them. If an error occurs during committing the changes, the user will be informed about it. The logs should be available for the user so that the y can be addressed in the future.
The bulk edit functionality should support expert users who are familiar with FOLIO data structure and are aware of the impact of the bulk edit operation (CSV approach) but also need to provide a way to a limited impact bulk edit that could be done by less technically savvy users (in-app approach). In the initial implementation the in-app approach should take precedence.
The planned functional areas for bulk edit include: inventory (item, holdings and instances), circulation (request and loans), Users (permission and user records), Acquisition (orders and finances), ERM (agreements and licenses), SRS (MARC bibliographic, holdings and authority) , and possibly others.
The implementation should consider large data (in millions of records) that will need to be processed. Multiple concurrent bulk edits will need to be supported. Also, support for multitenant environments and horizontal scaling is required.
Expected prerequisites
It is expected that back-end storage modules will implement optimistic locking (optimistic concurrency controls) for update operations. So the Bulk Operations application does not handle special cases when the records change between their selection, the modifications are chosen, and the edits are being applied. In the cases when target storage modules do not provide optimistic locking capabilities, there is a possibility for lost changes. Any additional effort related to adding optimistic locking to the back-end storage modules is out of scope for the Bulk Operation application.
The same behavior is expected from special APIs that should be used for update operations (e.g. changing the due date). It is expected from the API provider (a back-end module) to correctly handle "outdated" requests.
Implementation
For this application, a new concept is defined - the Bulk Operation Record. It represents the context used to execute a particular bulk operation and allows users to track their operations, pause those, and resume as needed. Also, it allows for the recovery of a bulk operation in the case of failure.
This new type of entity (Bulk Operation Record) will be encapsulated and handled in the new module dedicated to Bulk Operation functionality.
In general, the Bulk Operation consists of several steps:
- Retrieval of a list of entities based on the entity identifiers provided by a user as a CSV file or a CQL expression;
- Data editing. At this step, the user can either manually or semi-manually modify the retrieved records. These changes are not applied to the storage; they are kept locally.
- In the case of In-App Editing, the user defines a set of rules that will be applied to the records retrieved and presses the "Confirm changes" button.
- The data processing will be done asynchronously on the back-end side. The progress bar will be shown to the user in the case of massive data sets.
In the case of failure, the data processing can be restarted.
- The data processing will be done asynchronously on the back-end side. The progress bar will be shown to the user in the case of massive data sets.
- In the case of manual editing, the user uploads a CSV file with modified records.
- In the case of In-App Editing, the user defines a set of rules that will be applied to the records retrieved and presses the "Confirm changes" button.
- Preview Step. Then, the user can preview the preliminary results. In the case of massive data sets, just a subset of the records will be used for the preview.
- In the preview step, the user can download the CSV file containing modified records if needed or review the table representation in the preview form.
- If modified records are Ok, the user can press the "Commit changes" button.
- Applying changes to the storage and collecting results and errors.
Possible user actions:
- Start a Bulk Operation
A user can start a Bulk Operation by either providing CQL criteria or a CSV file with records identifiers. - Suspend a Bulk Operation
A user can suspend an active Bulk Operation at the "Applying changes" step. The Operation will be stopped at the current progress and can be resumed later. - Resume a suspended Bulk Operation
A user can resume a previously suspended Bulk Operation. In this case, the Operation will continue to process records starting from the record where it was suspended. - Resume after failure
A user can resume a previously failed Bulk Operation. In this case, the Operation will continue to process records starting from the point where a failure happened.
Bulk Operation States
| State | Description |
|---|---|
New | A Bulk Operation has just started. The user is either uploading a file with identifiers or creating CQL criteria. |
Retrieving records | The Data Export Job has been created and is processed by the Export Manager app. |
Saving records | At this step, the CSV file with retrieved records will be downloaded from Export Manager into the Bulk Edit shared storage. |
Data Modification | The user modifies the records either manually or using the In-App approach. |
Review Changes | Modifications have been applied to the records, the user is able to review them. |
Apply Changes | The changed records are sent to the respective back-end module to be stored in the database. |
Suspended | The user requested to suspend the "Apply changes" execution. |
Completed | The Bulk Operation was completed successfully, all records were processed successfully. (some records may still have errors). |
Completed with errors | The Bulk Operation was completed successfully, all records were processed, but some with errors. |
Cancelled | The user cancelled the Bulk Operation. Confirmation from the user is needed if this action is performed before the "Applying changes" step. If applying changes is in progress, there should be a warning to the users the data has been updated partially already. Again, the user must confirm cancellation. |
Scheduled | Reserved for future. |
Failed | The Bulk Operation was not completed. As a result, not all records have been processed. |
Diagrams
Below are the diagrams that represent the general flow of the Bulk Operation.
General Flow Diagram part 1:
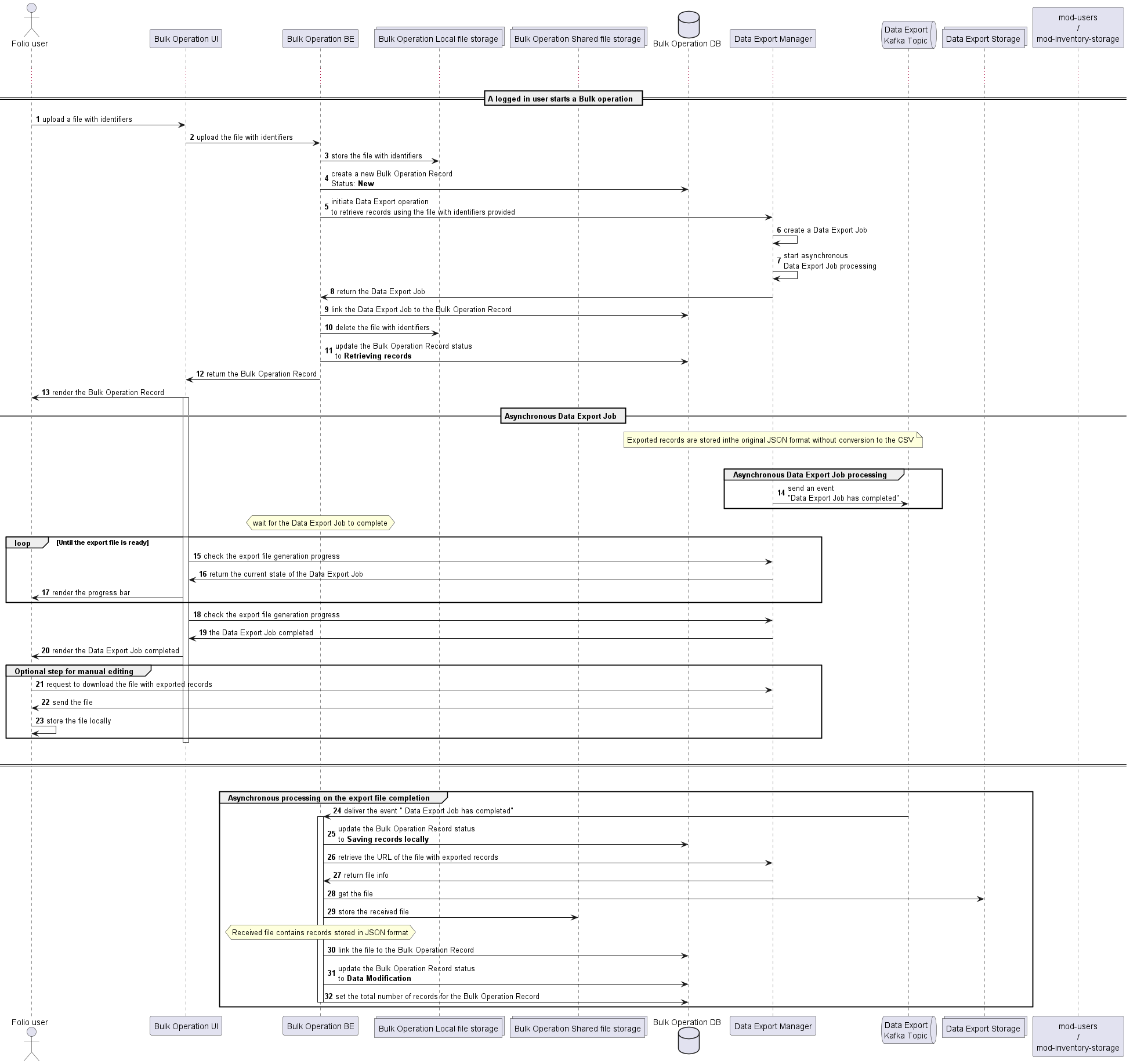
General Flow Diagram part 2:

This ER diagram represents the data model for the new module.
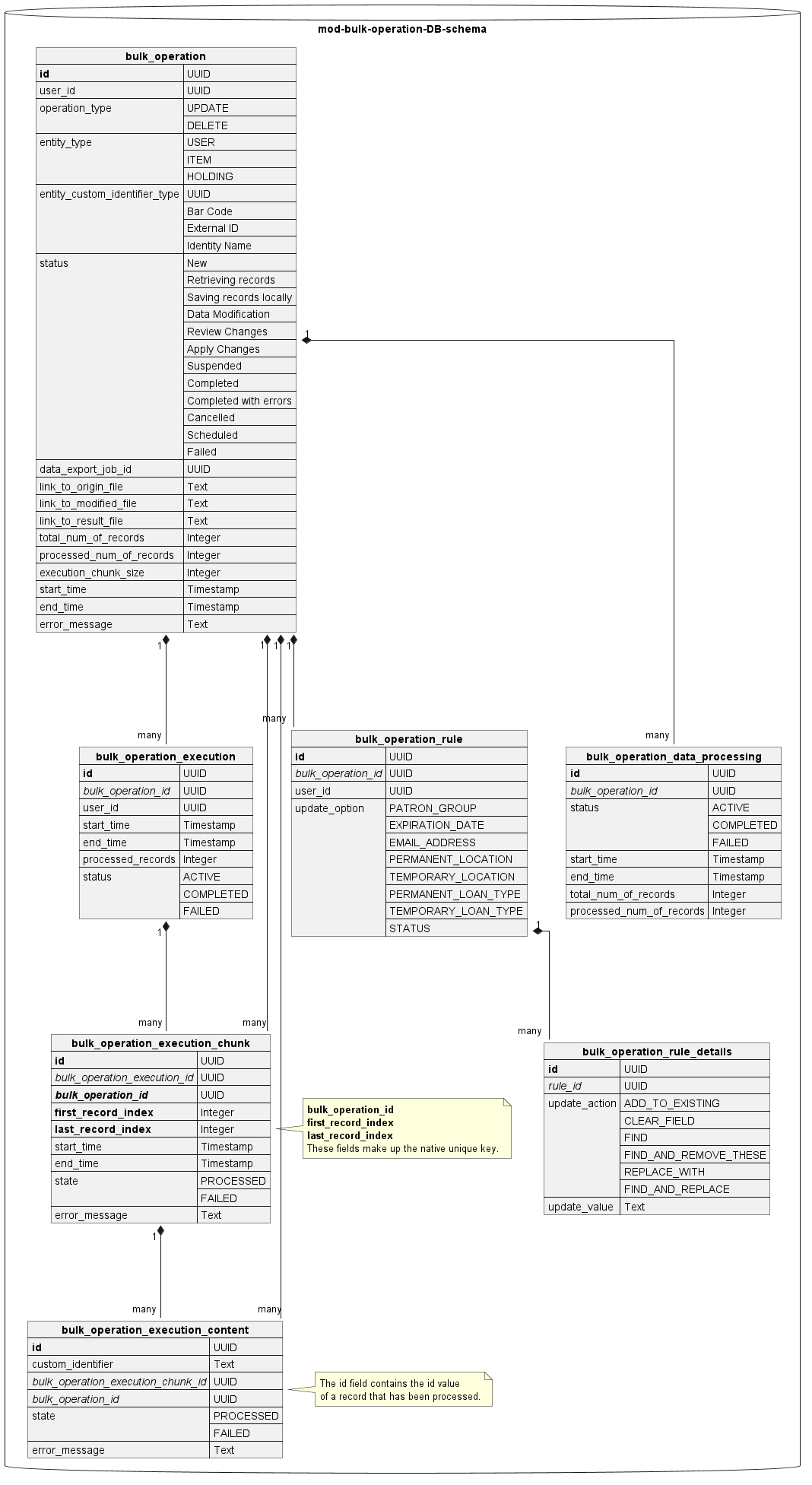
bulk_operation - this is the main table that represents any Bulk Operation.
buld_operation_rule - this table contains the rules that are/will be applied to a particular Bulk Operation in the case of the In-App approach for data modification.
- buld_operation_rule_details - this table contains the rules details
bulk_operation_data_processing - this table represents the state of the data processing operation when records retrieved from the Export Manager are processed according to the rules defined for a particular Bulk Operation. In the case of errors, this operation could be resumed.
bulk_operation_execution - this table represents an attempt to apply the changes to the target storage module. The changes are applied in chunks.
bulk_operation_execution_chunk - this table represents the chunk of the modified records that are sent to the target storage module to be stored.
bulk_operation_execution_content - this table holds the information for every particular modified record regarding if it has been successfully updated or not.
This component diagram represents the basic high-level structure for the new back-end module.
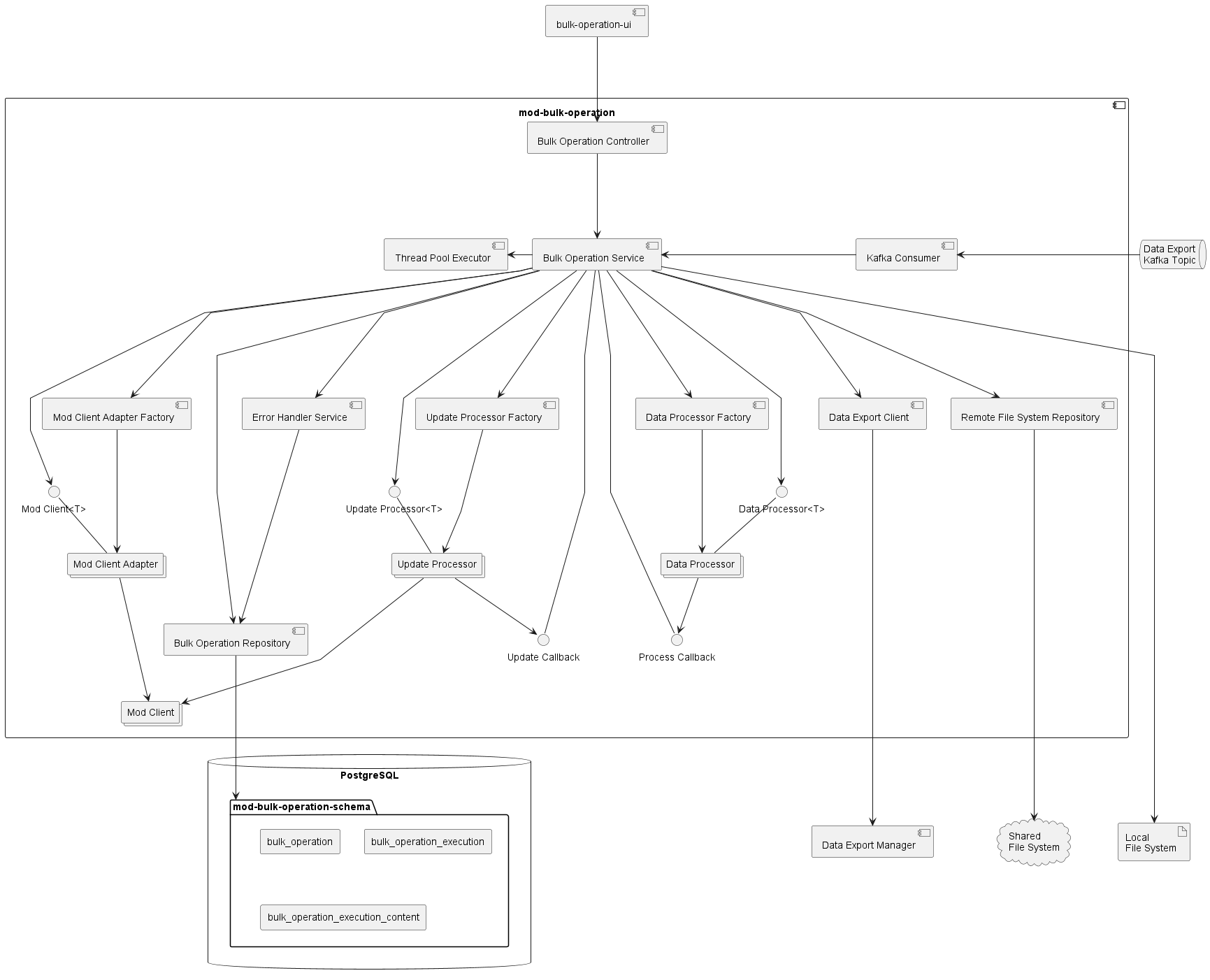
- Bulk Operation Controller - this component represents all end-points for the Bulk Operation beck-end module.
- Bulk Operation Service - it contains the implementation of all business logic for the Bulk Operation application.
- Error Handler Service - this component is responsible for error handling and storing errors in the database for further audit/analysis
- Thread Pool Executor - the component used by the Bulk Operation Service to run asynchronous tasks
- Kafka consumer - this component receives messages from the Data Export Manager it sends on completing the data export job. Once receives a message, the Kafka consumer passes control to the Bulk Operation Service.
- Data Export Client - it encapsulates the details of the HTTP interaction with the Data Export Manager.
- Remote File System Client - it encapsulates the details of interaction with S3-like storage that is available to all instances of the module.
- Bulk Operation Repository - it is a set of JPA repositories used to deal with the database.
- Mod Client - it is a set of clients that encapsulate the details of HTTP interaction with storage modules like mod-users, mod-inventory-storage, etc.
- Mod Client<T> - it is a generalized interface used by the Bulk Operation Service to retrieve actual data from different storage modules.
- Mod Client Adapter - this is a set of adapters used to cast Mod Clients to Mod Client<T> for Bulk Operation Service.
- Mod Client Adapter Factory - it is a component used to produce Mod Client Adapters by entity type.
- Data Processor<T> - this is a generalized interface used by the Bulk Operation Service to process a file with records using the rules specified by a user.
- Data Processor - this is a set of components that implement the logic for file processing for different entities.
- Data Processor Factory - this is a component used to produce Data Processors by entity type.
- Process Callback - this interface is used by the Data Processors to update the progress of processing. Bulk Operation Service implements this interface.
- Update Processor<T> - this is a generalized interface used by the Bulk Operation Service to update records in storage modules.
- Update Processor - it is a set of components that implement the logic for updating records in storage modules using a file as a source. Each Update Processor uses a corresponding Mod Client to perform HTTP calls to an appropriate backend module.
- Update Processor Factory - this is a component used by the Bulk Operation Service to produce Update Processors by entity type.
Unified table representation of data.
For the sake of simplicity, the back-end module uses the unified data structure to represent data for preview. It means that the UI application does not need to know the exact data type and/or data structure used to represent a particular type of entity. It simply receives the unified tabular data structure and renders the preview table for a user.
Below is the class diagram that represents the data structures used for that.
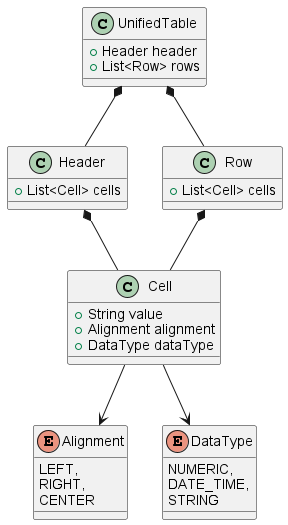
It makes sense to consider the usage of Query tool data structure to represent the results and preview to users.
BuklEditController implementation details
| Existing endpoint | New endpoint | Request | Response | Notes |
|---|---|---|---|---|
| /bulk-edit/{jobId}/upload | /bulk-edit/{jobId}/upload | csv-file | - | |
| /bulk-edit/{jobId}/item-content-update/upload | /bulk-edit/{operationId}/content-update/ | Collection<BulkOperationRule> | csv-file with preview of updated data (changes aren't committed yet) | |
| /bulk-edit/{jobId}/user-content-update/upload | ||||
| /bulk-edit/{jobId}/holdings/content-update/upload | ||||
| /{jobId}/preview/updated-items/download | /{operationId}/preview/download | - | csv-file with updated data (changes are committed and applied) | |
| /bulk-edit/{jobId}/preview/updated-users/download | ||||
| /bulk-edit/{jobId}/preview/updated-holdings/download | ||||
| /bulk-edit/{jobId}/preview/users | /bulk-edit/{operationId}/preview/ | - | UnifiedTable | |
| /bulk-edit/{jobId}/preview/items | ||||
| /bulk-edit/{jobId}/preview/holdings | ||||
| /bulk-edit/{jobId}/preview/errors | /bulk-edit/{operationId}/preview/errors | CQL-query | Errors | Returns list of errors, supports CQL-query for searching and filtering bulk operations. |
| /bulk-edit/{jobId}/start | /bulk-edit/{operationId}/start | - | BulkOperation | |
| /bulk-edit/{jobId}/roll-back | ||||
| /bulk-edit/operations | CQL-query | Collection<BulkOperation> | Returns list of bulk operations, supports CQL-query for searching and filtering bulk operations. |