data-import performance
MODDATAIMP-124 - Getting issue details... STATUS
Data-import process currently consists of a few stages. Uploaded file is being chunked, records from each chunk are parsed, saved to storage as Source Records, mapped to Instances, saved to Inventory, and corresponding instanceIds are set to Source Records. Chunk size and the number of chunks being processed simultaneously can be changed (by default it's 50 and 10 respectively).
.png?version=1&modificationDate=1561466802000&cacheVersion=1&api=v2)
The actual data import starts at the point when file is uploaded. Right now, that can only be triggered by the so-called "secret" button, which triggers a default job to import MARC bibliographic records into SRS and create associated Inventory instances. This calls the POST endpoint /data-import/uploadDefinitions/{uploadDefinitionId}/processFiles
Import is considered finished when all the chunks are processed successfully or marked as ERROR, appropriate JobExecution status is set and the file is visible in the logs section on the UI.
Files used for testing:
msplit30000.mrc contains 30,000 raw MARC bibliographic records, RecordsForSRS_20190322.json contains 28,306 MARC records in json format.
Performance was measured on https://folio-snapshot-load.aws.indexdata.com with default chunk size and queue size parameters (50 and 10 respectively).
Environment characteristics: AWS t2.xlarge instance (4 CPUs, 16 GB RAM)
It consistently takes 8 min to load each of the files, which makes about 17 sec to load 1000 records.
Data-import performance was also tested locally on folio-testing-backend Vagrant box version 5.0.0-20190619.2334 (2 CPUs, 16 GB RAM) with mod-source-record-manager and mod-data-import deployed additionally. For each module running on a docker container was allocated 256 MB of JVM heap memory.
Results are shown below, default values are highlighted. In average, it takes about 25 sec per 1000 raw MARC records and about 22 sec per 1000 json records.
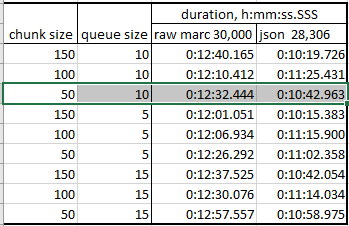
Testing results are better on the AWS environment because it has more computing power.
Conclusions
Before concept of batch operations was introduced importing of 30,000 raw MARC records took about 38-40 min on the local environment. Performing Steps 4, 8 and 13 at the diagram above with batch save/update drastically decreased the number of http requests between the modules. Before it took more then 200 requests to process a chunk of 50 records (Steps 4, 8, 9 and 13 on the diagram), waiting for the responses significantly slowed down the process. With Steps 4, 8 and 13 as batch operations it now requires 53 http calls to do the same. It is fair to assume that implementing batch save to mod-inventory-storage (Step 9 at the diagram) will improve the data-import performance a bit more MODINVSTOR-291 - Getting issue details... STATUS . However, main improvements in performance are expected with applying of event driven approach UXPROD-1806 - Getting issue details... STATUS .